Prefab Founding Engineer. Three-time dad. Polyglot. I am a pleaser. He/him.
If you're just starting the LSP, you might wonder what language to build your Language Server (LS) with. This article will help you pick the right language. You can choose anything (seriously, I built a toy Language Server in Bash). There's no universally correct answer, but there’s a correct one for you.
Your audience is the most important consideration. If you're writing a language server for a new Python web framework (Language Servers aren't just for languages, people), then implementing the language server in Java might raise a few eyebrows.
The audience for a Python framework is less likely to contribute to a language server written in a language they're less familiar with. There's nothing wrong with Java (IMHO), but the biases associated with languages could hurt adoption.
If your language server is for a specific language or tooling tied to a specific language, you should probably use the same language to build the server.
If you're building your language server as a hobby, the first user is yourself. Optimize for your own enjoyment.
You’re less likely to have fun building if you pick a popular language with unfamiliar (or poor) ergonomics. If you're not having fun, you're less likely to get very far with the project, and your language server won't ever matter to anyone else anyway.
This doesn't mean you should limit yourself to languages you're already an expert in -- building a language server is a great way to learn how a new language handles
Unless you're building a language server to replace one that is demonstrably slow, you should probably avoid optimizing your decision for performance. Measure first before you start hand-coding assembly code.
You're a developer; I get it. You want to think performance matters. Suppose computationally intensive behaviors are required to calculate diagnostics/code actions/etc. In that case, you can always shell out to something tuned for performance and still keep the Language Server itself implemented at a higher level.
Don't worry about performance. It isn't important at first, and you have options later.
Many languages already have libraries that provide abstractions to help you write language servers. These can jump-start your development but aren't going to make or break your project.
You have all the building blocks you need if you can read and write over stdin/stdout and encode and decode JSON.
Learn more and build alongside me in my LSP From Scratch series.
You can build a language server without third-party libraries.
If the considerations above haven't helped you pick a clear winner, choose TypeScript (or, if you must, JavaScript).
The first-party libraries (e.g., vscode-languageserver-node) are in written TypeScript, and the community and ecosystem are excellent. A discussion on the vscode-languageserver-node project often leads to an update to the spec itself.
As a bonus, servers written in TypeScript (and JavaScript) can be bundled inside a VS Code extension and be available in the VS Code Marketplace as a single download. I've put up a Minimum Viable VS Code Language Server Extension repo where you can see how this all fits together.
Lograge is one of the all-time great Rails gems and is one of those 3-4 gems like devise, timecop or rails_admin that I typically install on every new Rails project.
So, lograge is great, but are better alternatives in 2024? I think so. We'll examine two options: an excellent free choice called Rails Semantic Logger and one I've built for the Prefab platform.
First, let's take a quick look at what problem we're trying to solve. Here's the logging you get from Rails & Lograge out of the box at info level.
Rails @ Info
LogRage @ Info
Started GET "/posts" for 127.0.0.1 at 2023-09-06 10:08:20 -0400 Processing by PostsController#index as HTML Rendered posts/index.html.erb within layouts/application (Duration: 0.8ms | Allocations: 813) Rendered layout layouts/application.html.erb (Duration: 19.3ms | Allocations: 34468) Completed 200 OK in 30ms (Views: 21.1ms | ActiveRecord: 0.5ms | Allocations: 45960)
But, a single-line request summary is not the only interesting aspect of logging. What about debug logging? What about tagged and struct logging? Can any of these libraries help us fix our problems faster?
To exercise the other aspects of logging, here's the sample code we will run. It logs at all four levels and uses tagged and structlog to show how to add context to your logs.
classPostsController< ApplicationController defindex @posts= Post.all if can_use_struct_log? logger.debug "🍏🍏🍏detailed information",posts:@posts.size #struct logging logger.info "🍋🍋🍋informational logging",posts:@posts.size else logger.debug "🍏🍏🍏detailed information #{@posts.size}"# old-school logger.info "🍋🍋🍋informational logging #{@posts.size}" end @posts.first.process_post end end classPost< ApplicationRecord defprocess_post logger.tagged "process post"do logger.tagged "post-#{id}"do#nested tagged logging logger.debug "🍏🍏🍏details of the post" logger.info "🍋🍋🍋 info about the post" end end end end
Let's compare the output at the info level for each of the gems. It is a bit funky to see it on the web and not a wide terminal, but we'll do our best. Each of the gems does provide a way to provide a custom formatter to tweak things like date, time, etc, but this is what you get out of the box. Also, you'll probably want to use JSON output in production. All the gems support that; see the JSON output comparison in the appendix, but it's pretty straightforward.
Rails @ Info
LogRage @ Info
SemanticRails @ Info
Prefab @ Info
Started GET"/posts"for127.0.0.1 at 2023-09-0610:08:20-0400 Processing by PostsController#index as HTML 🍋🍋🍋informational logging 1 [process post][post-2] 🍋🍋🍋 info about the post Rendered posts/index.html.erb within layouts/application (Duration:0.8ms | Allocations:813) Rendered layout layouts/application.html.erb (Duration:19.3ms | Allocations:34468) Completed 200OKin30ms (Views:21.1ms | ActiveRecord:0.5ms | Allocations:45960)
We see that Rails, by default, has no support for structured logging, though it does support tagged logging. We're outputting logging 1 instead of logging posts=1 and in JSON we won't have a nice {"posts": 1} to index.
It's also not clear what class or file informational logging 1 is coming from. This is annoying because it makes us need to type more detail into the error message just to help us locate / grep.
We do see helpful logging about what templates were rendered and how long they took.
🍋🍋🍋informational logging 1 [process post][post-2] 🍋🍋🍋 info about the post method=GET path=/posts format=html controller=PostsController action=index status=200 allocations=46692 duration=32.37 view=21.32 db=0.80
Lograge also does not support structure logging, so no nice {"posts": 1} in our JSON.
It's also not clear where our logging is coming from because it doesn't list the class name.
Lograge has removed the template and request start logging at the info level.
At the info level, we can start to see what SemanticRails brings to the table. The big help is that we're also outputting the class names: PostsController and Post which helps us orient about where these messages are coming from.
We can see the { :posts => 1 } from our structured logging as well as the [process post] and [post-2]` tags, and we can see the single-line request summary at the end.
If you notice in the Rails logs, there is information about what templates were rendered. SemanticRails has reclassified this info logging to only output at the debug level.
INFOStartedGET"/"for::1 at 2023-11-2015:04:07-0500 path=rails.rack.logger.call_app INFOProcessing by PostsController#index as HTML path=active_support.log_subscriber.info INFO 🍋🍋🍋informational logging path=app.controllers.posts_controller.index posts=1 INFO 🍋🍋🍋 info about the post log.tags=["process post","post-2"] path=app.models.post.process_post INFORendered posts/index.html.erb within layouts/application (Duration:1.8ms |Allocations:1516) path=active_support.log_subscriber.info INFORendered layout layouts/application.html.erb (Duration:24.8ms |Allocations:35463) path=active_support.log_subscriber.info INFOCompleted200OK in 42ms (Views:26.7ms |ActiveRecord:0.6ms |Allocations:52173) path=active_support.log_subscriber.info INFO200PostsController#index action=index controller=PostsController db_runtime=0.62 format=html method=GET path=rails.controller.request req_path=/ status=200 view_runtime=26.72
Like SemanticRails, Prefab supports structured logging and adds the path to the log line: 🍋🍋🍋 informational logging path=app.controllers.posts_controller.index posts=1.
Prefab also adds a helpful single-line summary of the request.
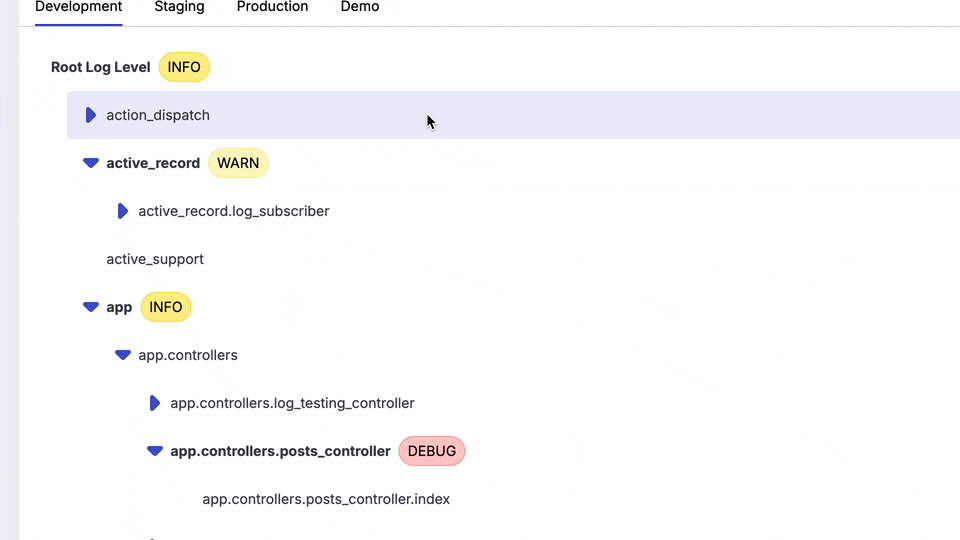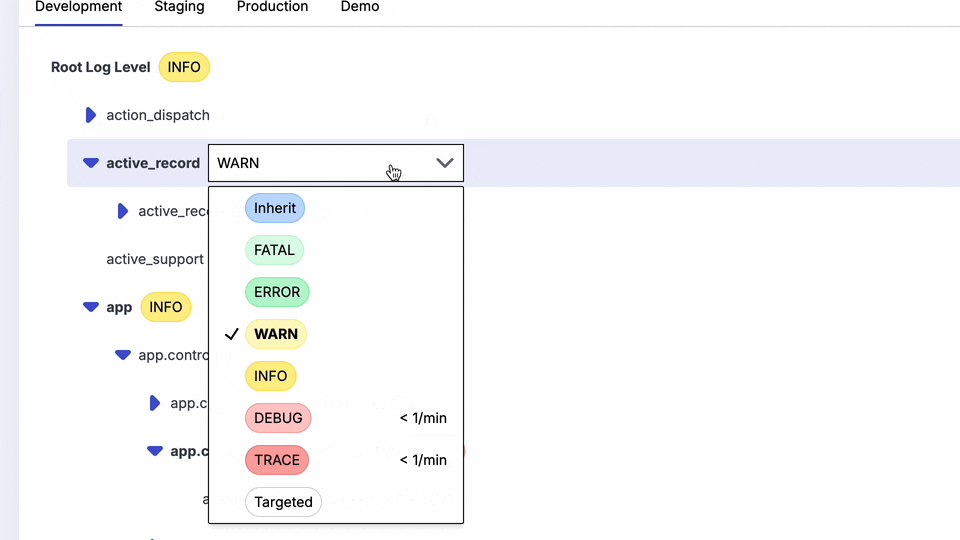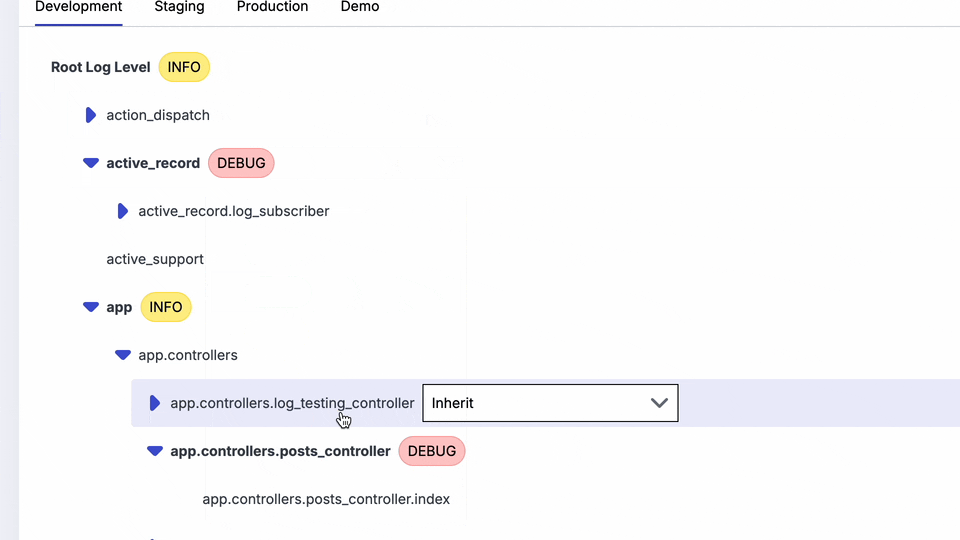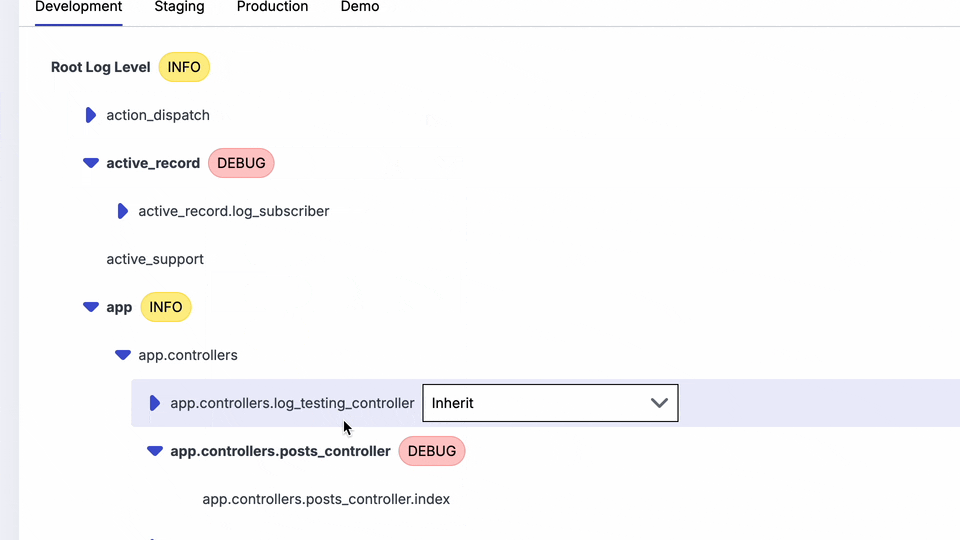
Prefab has not removed the layout rendering and other request logging. Prefab's philosophy is that it should output all the logs but give you easy ways to turn them on and off.
You can quickly turn logs on and off via the UI in any environment:
For completeness, let's compare the output at the debug level for each of the gems.
Rails @ Debug
LogRage @ Debug
SemanticRails @ Debug
Prefab @ Debug
Started GET"/posts"for127.0.0.1 at 2023-09-0610:01:55-0400 Processing by PostsController#index as HTML Post Count (0.0ms)SELECTCOUNT(*)FROM"posts" ↳ app/controllers/posts_controller.rb:8:in `index' 🍏🍏🍏detailed information 1 CACHE Post Count (0.0ms)SELECTCOUNT(*)FROM"posts" ↳ app/controllers/posts_controller.rb:9:in `index' 🍋🍋🍋informational logging 1 CACHE Post Count (0.0ms)SELECTCOUNT(*)FROM"posts" ↳ app/controllers/posts_controller.rb:10:in `index' CACHE Post Count (0.0ms)SELECTCOUNT(*)FROM"posts" ↳ app/controllers/posts_controller.rb:11:in `index' Post Exists?(0.1ms)SELECT1AS one FROM"posts"LIMIT?[["LIMIT",1]] ↳ app/controllers/posts_controller.rb:12:in `index' Post Load (0.0ms)SELECT"posts".*FROM"posts"ORDERBY"posts"."id"ASCLIMIT?[["LIMIT",1]] ↳ app/controllers/posts_controller.rb:13:in `index' [process post][post-2] 🍏🍏🍏details of the post [process post][post-2] 🍋🍋🍋 info about the post Rendering layout layouts/application.html.erb Rendering posts/index.html.erb within layouts/application Post Load (0.1ms)SELECT"posts".*FROM"posts" ↳ app/views/posts/index.html.erb:4 Rendered posts/index.html.erb within layouts/application (Duration:0.6ms | Allocations:736) Rendered layout layouts/application.html.erb (Duration:7.9ms | Allocations:14135) Completed 200OKin15ms (Views:8.4ms | ActiveRecord:0.6ms | Allocations:20962)
Rails debug for local dev gets pretty chatty with a lot more detail. In addition to the templates and layouts we got at the debug level, we can now see the executed SQL.
We also now get class and line number output for some of the logging, though not all of it. Our custom logging does not include any information about where it came from.
It's also a lot of output, and it's not particularly easy to grep for the important bits. As your app grows, this logging can start to get a bit overwhelming.
It may go without saying, but turning this on in production would be a very bad idea.
Post Count (0.3ms)SELECTCOUNT(*)FROM"posts" ↳ app/controllers/posts_controller.rb:8:in `index' 🍏🍏🍏detailed information 1 CACHE Post Count (0.0ms)SELECTCOUNT(*)FROM"posts" ↳ app/controllers/posts_controller.rb:9:in `index' 🍋🍋🍋informational logging 1 CACHE Post Count (0.0ms)SELECTCOUNT(*)FROM"posts" ↳ app/controllers/posts_controller.rb:10:in `index' CACHE Post Count (0.0ms)SELECTCOUNT(*)FROM"posts" ↳ app/controllers/posts_controller.rb:11:in `index' Post Exists?(0.1ms)SELECT1AS one FROM"posts"LIMIT?[["LIMIT",1]] ↳ app/controllers/posts_controller.rb:12:in `index' Post Load (0.0ms)SELECT"posts".*FROM"posts"ORDERBY"posts"."id"ASCLIMIT?[["LIMIT",1]] ↳ app/controllers/posts_controller.rb:13:in `index' [process post][post-2] 🍏🍏🍏details of the post [process post][post-2] 🍋🍋🍋 info about the post Post Load (0.1ms)SELECT"posts".*FROM"posts" ↳ app/views/posts/index.html.erb:4 method=GET path=/posts format=html controller=PostsController action=index status=200 allocations=49556 duration=33.84 view=22.60 db=0.73
Lograge is pretty much the same as the Rails logger when it comes to debugging. Lograge's approach is to help you solve logging in production, so it leans on the existing Rails formatting for local dev.
2023-11-2015:28:07.318919D[16770:puma srv tp 003 remote_ip.rb:93] Rack -- Started --{:method=>"GET",:path=>"/",:ip=>"::1"} 2023-11-2015:28:07.336737D[16770:puma srv tp 003](0.072ms) ActiveRecord -- ActiveRecord::SchemaMigration Pluck --{:sql=>"SELECT \"schema_migrations\".\"version\" FROM \"schema_migrations\" ORDER BY \"schema_migrations\".\"version\" ASC",:allocations=>39,:cached=>nil} 2023-11-2015:28:07.350951D[16770:puma srv tp 003 subscriber.rb:149] PostsController -- Processing #index 2023-11-2015:28:07.355143D[16770:puma srv tp 003 posts_controller.rb:5](0.262ms) ActiveRecord -- Post Count --{:sql=>"SELECT COUNT(*) FROM \"posts\"",:allocations=>21,:cached=>nil} 2023-11-2015:28:07.355179D[16770:puma srv tp 003 posts_controller.rb:5] PostsController -- 🍏🍏🍏detailed information --{:posts=>1} 2023-11-2015:28:07.355336D[16770:puma srv tp 003 posts_controller.rb:6](0.004ms) ActiveRecord -- Post Count --{:sql=>"SELECT COUNT(*) FROM \"posts\"",:allocations=>3,:cached=>true} 2023-11-2015:28:07.355346I[16770:puma srv tp 003 posts_controller.rb:6] PostsController -- 🍋🍋🍋informational logging --{:posts=>1} 2023-11-2015:28:07.355459D[16770:puma srv tp 003 posts_controller.rb:7](0.004ms) ActiveRecord -- Post Count --{:sql=>"SELECT COUNT(*) FROM \"posts\"",:allocations=>3,:cached=>true} 2023-11-2015:28:07.355604D[16770:puma srv tp 003 posts_controller.rb:8](0.004ms) ActiveRecord -- Post Count --{:sql=>"SELECT COUNT(*) FROM \"posts\"",:allocations=>3,:cached=>true} 2023-11-2015:28:07.356317D[16770:puma srv tp 003 posts_controller.rb:16](0.061ms) ActiveRecord -- Post Exists?--{:sql=>"SELECT 1 AS one FROM \"posts\" LIMIT ?",:binds=>{:limit=>1},:allocations=>28,:cached=>nil} 2023-11-2015:28:07.357050D[16770:puma srv tp 003 posts_controller.rb:17](0.045ms) ActiveRecord -- Post Load --{:sql=>"SELECT \"posts\".* FROM \"posts\" ORDER BY \"posts\".\"id\" ASC LIMIT ?",:binds=>{:limit=>1},:allocations=>57,:cached=>nil} 2023-11-2015:28:07.360796D[16770:puma srv tp 003 post.rb:19][process post][post-2] Post -- 🍏🍏🍏details of the post 2023-11-2015:28:07.360853I[16770:puma srv tp 003 post.rb:20][process post][post-2] Post -- 🍋🍋🍋 info about the post 2023-11-2015:28:07.365288D[16770:puma srv tp 003 fanout.rb:207] ActionView -- Rendering --{:template=>"posts/index.html.erb"} 2023-11-2015:28:07.366600D[16770:puma srv tp 003 index.html.erb:4](0.108ms) ActiveRecord -- Post Load --{:sql=>"SELECT \"posts\".* FROM \"posts\"",:allocations=>57,:cached=>nil} 2023-11-2015:28:07.366907D[16770:puma srv tp 003 subscriber.rb:149](1.513ms) ActionView -- Rendered --{:template=>"posts/index.html.erb",:within=>"layouts/application",:allocations=>1101} 2023-11-2015:28:07.396876I[16770:puma srv tp 003 subscriber.rb:149](45.8ms) PostsController -- Completed #index -- { :controller => "PostsController", :action => "index", :format => "HTML", :method => "GET", :path => "/", :status => 200, :view_runtime => 32.75, :db_runtime => 0.75, :allocations => 51109, :status_message => "OK" }
At the debug level, SemanticRails really starts to show off. It does a nice job of doing structured logging for ActiveRecord loads: ActiveRecord -- Post Load -- { :sql => "SELECT \"posts\".* FROM \"posts\"", :allocations => 57, :cached => nil }.
This structure helps you grep and search through the log lines. You also have a ton of options for getting the logging just the way you like it. https://logger.rocketjob.io/rails.html has a lot more details.
I also turned on config.semantic_logger.backtrace_level = :debug, which lets us even see the file and line number like posts_controller.rb:8 or fanout.rb:207.
INFOStartedGET"/"for::1 at 2023-11-2015:04:07-0500 path=rails.rack.logger.call_app INFOProcessing by PostsController#index as HTML path=active_support.log_subscriber.info DEBUGPostCount(0.0ms)SELECTCOUNT(*)FROM"posts" path=active_support.log_subscriber.debug DEBUG ↳ app/controllers/posts_controller.rb:5:in `index' path=active_record.log_subscriber.log_query_source DEBUG 🍏🍏🍏detailed information path=app.controllers.posts_controller.index posts=1 DEBUGCACHEPostCount(0.0ms)SELECTCOUNT(*)FROM"posts" path=active_support.log_subscriber.debug DEBUG ↳ app/controllers/posts_controller.rb:6:in `index' path=active_record.log_subscriber.log_query_source INFO 🍋🍋🍋informational logging path=app.controllers.posts_controller.index posts=1 DEBUGCACHEPostCount(0.0ms)SELECTCOUNT(*)FROM"posts" path=active_support.log_subscriber.debug DEBUG ↳ app/controllers/posts_controller.rb:7:in `index' path=active_record.log_subscriber.log_query_source DEBUGCACHEPostCount(0.0ms)SELECTCOUNT(*)FROM"posts" path=active_support.log_subscriber.debug DEBUG ↳ app/controllers/posts_controller.rb:8:in `index' path=active_record.log_subscriber.log_query_source DEBUGPostExists?(0.1ms)SELECT1AS one FROM"posts"LIMIT?[["LIMIT",1]] path=active_support.log_subscriber.debug DEBUG ↳ app/controllers/posts_controller.rb:16:in `index' path=active_record.log_subscriber.log_query_source DEBUGPostLoad(0.1ms)SELECT"posts".* FROM"posts"ORDERBY"posts"."id"ASCLIMIT?[["LIMIT",1]] path=active_support.log_subscriber.debug DEBUG ↳ app/controllers/posts_controller.rb:17:in `index' path=active_record.log_subscriber.log_query_source DEBUG 🍏🍏🍏details of the post log.tags=["process post","post-2"] path=app.models.post.process_post INFO 🍋🍋🍋 info about the post log.tags=["process post","post-2"] path=app.models.post.process_post DEBUGRendering layout layouts/application.html.erb path=active_support.log_subscriber.debug DEBUGRendering posts/index.html.erb within layouts/application path=active_support.log_subscriber.debug DEBUGPostLoad(0.1ms)SELECT"posts".* FROM"posts" path=active_support.log_subscriber.debug DEBUG ↳ app/views/posts/index.html.erb:4 path=active_record.log_subscriber.log_query_source INFORendered posts/index.html.erb within layouts/application (Duration:1.8ms |Allocations:1516) path=active_support.log_subscriber.info INFORendered layout layouts/application.html.erb (Duration:24.8ms |Allocations:35463) path=active_support.log_subscriber.info INFOCompleted200OK in 42ms (Views:26.7ms |ActiveRecord:0.6ms |Allocations:52173) path=active_support.log_subscriber.info INFO200PostsController#index action=index controller=PostsController db_runtime=0.62 format=html method=GET path=rails.controller.request req_path=/ status=200 view_runtime=26.72
Prefab aims for a middle road of readability/complexity.
Instead of fine-tuning your output by changing a configuration file. Prefab's has a UI to toggle on things like the template messages or active record SQl, so that you can see it only when you need it. The fun bit is that you can also do this in staging or production. Read more about dynamic log levels.
You can also target this verbose logging like you would a feature flag so that it's only on for a particular user or transaction that is causing issues.
This is a big deal, because it means you can now turn on debugging on in production. You can't realistically do that with the other gems. The key is the targeting. We still won't turn on ALL debugging, but with rules we can just turn it on for a particular class, or go even more specific by turning on debug logging for a particular user for 5 minutes and you may be able to debug your issues without having to redeploy.
{ "host":"My-MacBook-Pro.local", "application":"Semantic Logger", "environment":"development", "timestamp":"2023-09-06T14:18:33.507019Z", "level":"info", "level_index":2, "pid":67151, "thread":"puma srv tp 001", "file":"/Users/me/RubymineProjects/RailsLoggingTestApplication/app/models/post.rb", "line":17, "tags":["process post", "post-2"], "name":"Post", "message":"🍋🍋🍋 info about the post" }
{ "severity":"INFO", "datetime":"2023-11-20T13:15:47.502-05:00", "path":"app.models.post.process_post", "message":"🍋🍋🍋 info about the post ", "log.tags":["process post", "post-2"] }
The state of Rails logging gems in 2024 is good, and you've got great options. If you've been defaulting to just standard Rails logging or lograge for years, it may be time to take a look at what else is out there. Being able to quickly trace each log line back to its source is valuable, and structured logging feels much better than string interpolation and can be very powerful in conjunction with your log aggregation tool.
Rails Semantic Logger is an impressive piece of software that has been around for a long time. It's got a lot of features and is very configurable. It has everything you could want in a logger, save the ability to update it dynamically.
logger.measure_trace("Low level trace information such as data sent over a socket") do ... end is cool
logger.error("Oops external call failed", exception) is cool
Bad:
Can't change log levels on the fly
tip
Since this was published, prefab-cloud-ruby has switched to work as a filter for rails_semantic_logger. That means you can have your cake and eat it too! Just add SemanticLogger.add_appender(filter: Prefab.log_filter) and you can get the best of both worlds. Read Dynamic Ruby Log Levels With Semantic Logger & Prefab for details.
Prefab is a SaaS that provides dynamic configuration and uses that to support Feature Flag and Dynamic Log Levels. Prefab provides the same log cleanup and core features as SemanticRails, with the additional benefit of being able to quickly debug production by temporarily enabling debug logging for a specific user or job.
We're super excited about our new Editor Tools! When Jeffrey first starting hacking around with the LSP we each had one of those whoa moments where you feel like you're seeing things in a whole new light.
I love being in my editor, but everything about Feature Flags has always required me to leave. We spent the past month asking "what would it be like to do it all from the editor?" and I love where we ended up.
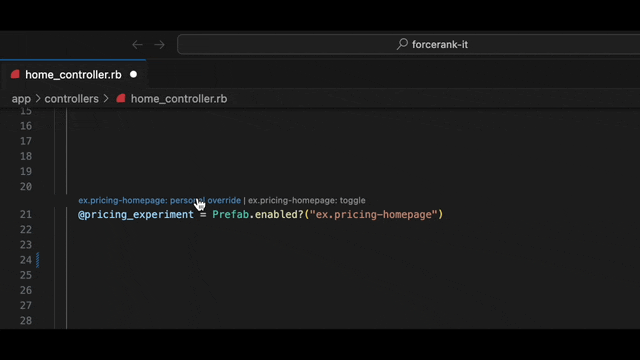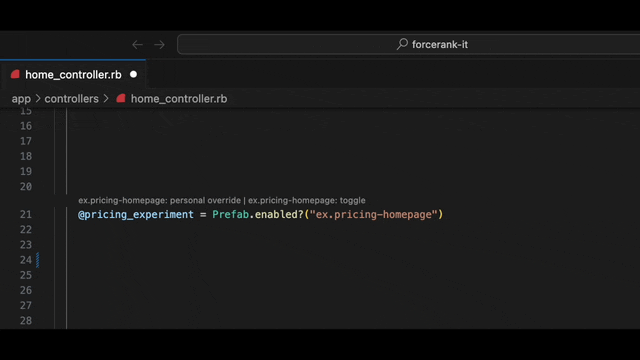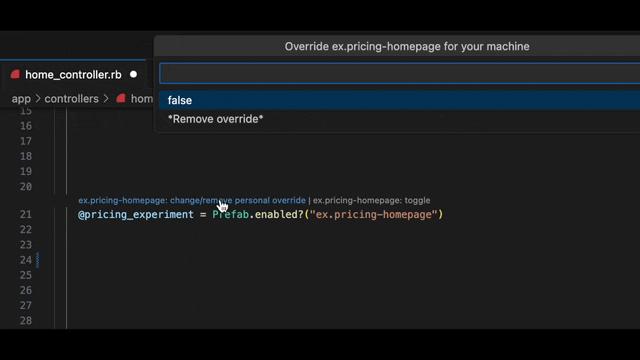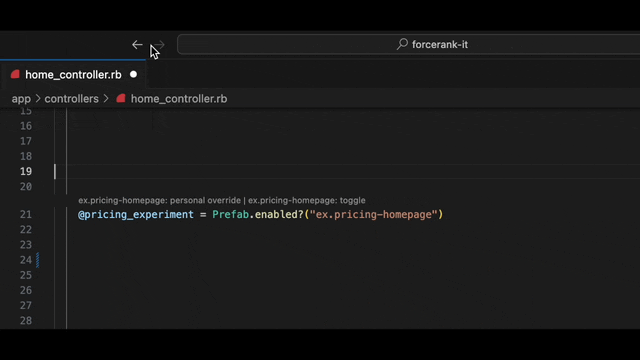
First up, the autocomplete feature for feature flags. A mistyped feature flag is a terrible thing and pretty annoying to debug since they default to false. Let your editor help with that. Autocomplete for flag and config names, and auto-create simple flags if the flag doesn't exist yet.
Writing the feature flag is often the easy part. The real question comes later. Is this thing on? Can I delete it? What value is set in production?
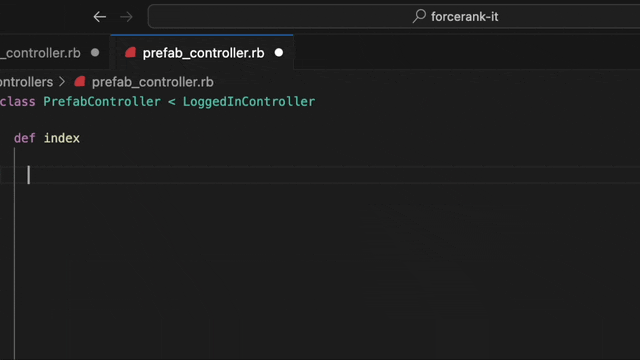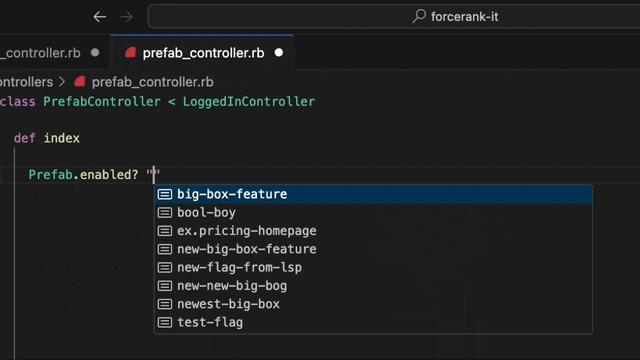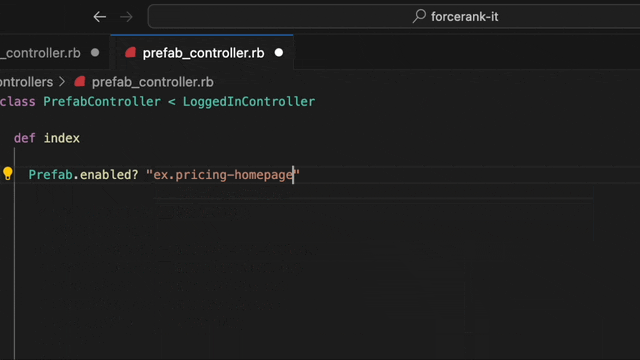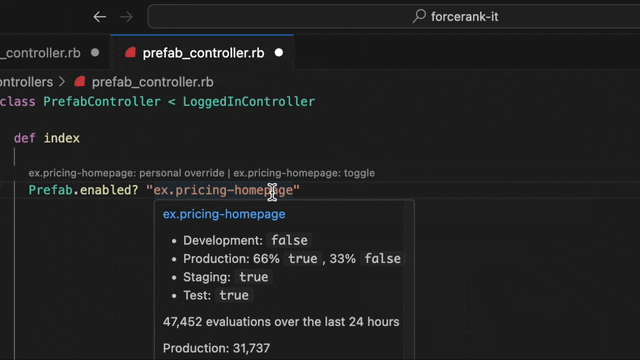
We wondered how excellent it would be to bring our evaluation data right into the editor and our answer is... very excellent! No more leaving your editor to answer a simple question. A simple hover, and you’ve got all the info you need.
In this picture you can see that the flag is true in staging and test, false in dev and a 66% rollout to true in production. And it looks like it's working too. Data over the past 24 hours shows that 67% of users are seeing the feature.
Grimace if you've ever committed if true || flags.enabled? "myflag" to version control. It's easy to do. You want to see what happens when a flag is enabled, but setting the flag is annoying or will change it for everyone, so you cheat and put a raw true in front of your flag and then forget to take it out.
What would be a better way? Well, could I just click on the flag and set it to true? Of course it should only be true for me on my personal machine so I don't screw anyone else up. That sounds nice right?
This personal overrides feature is tied to you developer account, so no more global toggles causing chaos. Set your value, test your feature, all without leaving your coding groove.
We've been learning a ton about Language Server Protocols (LSPs) lately. Jeffrey's been on a roll, sharing his insights on creating LSPs with tutorials like writing an lsp in bash and lsp zero to completion.
We're not just building these tools for you; we're building them for us, too. We're genuinely jazzed about these new features and the difference they're making in our coding lives.
Give these new tools a spin and let us know what you think. We'd love to hear about what else you think would make the in-editor experience for feature flags brilliant. Don't use VSCode? Don't worry, we're working on the other editors too. Go here to get notified about new editor releases.
This gives us a value for $line that looks like Content-Length: 3386
The content length will vary based on the capabilities of your editor, but the gist here is that we need to read 3386 characters to get the entire JSON payload.
Let's extract the content length number
while IFS= read -r line; do # Capture the content-length header value [[ "$line" =~ ^Content-Length:\ ([0-9]+) ]] length="${BASH_REMATCH[1]}"
We need to add 2 to the number to account for the initial \r after the content length header. So we'll length=$((length + 2))
Now we're ready to read the JSON payload:
while IFS= read -r line; do # Capture the content-length header value [[ "$line" =~ ^Content-Length:\ ([0-9]+) ]] length="${BASH_REMATCH[1]}" # account for \r at end of header length=$((length + 2)) # Read the message based on the Content-Length value json_payload=$(head -c "$length")
Remember that JSON-RPC requires us to include the id of the request message in our response. We could write some convoluted JSON parsing in bash to extract the id, but we'll lean on jq instead.
while IFS= read -r line; do # Capture the content-length header value [[ "$line" =~ ^Content-Length:\ ([0-9]+) ]] length="${BASH_REMATCH[1]}" # account for \r at end of header length=$((length + 2)) # Read the message based on the Content-Length value json_payload=$(head -c "$length") # We need -E here because jq fails on newline chars -- https://github.com/jqlang/jq/issues/1049 id=$(echo -E "$json_payload" | jq -r '.id')
Now, we have everything we need to read and reply to our first message.
The first message sent by the client is the initialize method. It describes the client's capabilities to the server.
You can think of this message as saying, "Hey, language server, here are all the features I support!"
The server replies with, "Oh, hi, client. Given the things you support, here are the things I know how to handle."
Well, that's how it should work, anyway. For our MVP here, we'll provide a canned response with an empty capabilities section.
while IFS= read -r line; do # Capture the content-length header value [[ "$line" =~ ^Content-Length:\ ([0-9]+) ]] length="${BASH_REMATCH[1]}" # account for \r at end of header length=$((length + 2)) # Read the message based on the Content-Length value json_payload=$(head -c "$length") # We need -E here because jq fails on newline chars -- https://github.com/jqlang/jq/issues/1049 id=$(echo -E "$json_payload" | jq -r '.id') method=$(echo -E "$json_payload" | jq -r '.method') case "$method" in 'initialize') respond '{ "jsonrpc": "2.0", "id": '"$id"', "result": { "capabilities": {} } }' ;; *) ;; esac done
We pluck out the request's method and use a case statement to reply to the correct method. If we don't support the method, we don't respond to the client.
If we didn't use a case statement here and always replied with our canned message, we'd make it past initialization, but then the client would get confused when we respond to (e.g.) its request for text completions with an initialize result.
That's all you need for a minimum viable language server built-in bash. It doesn't do anything besides the initialization handshake, but it works.
In 56 lines of bash, we've implemented a usable (if boring) language server.
I wouldn't advocate anyone writing a serious language server in bash. Hopefully, this has illustrated how easy it is to get started with language servers and has made the LSP and JSON-RPC a little less magical.
What language would I recommend for writing a language server? That's probably a whole article in itself, but the short answer is
All things being equal, choose TypeScript. The first-party libraries (e.g., vscode-languageserver-node) are in written TypeScript, and the community and ecosystem are excellent.
If you don't want to use TypeScript, use whatever language you're most productive in. There's probably already a library for writing a language server in your preferred language, but if there isn't, you now know how easy it is to write it yourself.
import fetch from"node-fetch"; import{ createConnection, InitializeResult, TextDocumentSyncKind, TextDocuments, }from"vscode-languageserver/node"; import{ TextDocument }from"vscode-languageserver-textdocument"; const connection =createConnection(); const documents: TextDocuments<TextDocument>=newTextDocuments(TextDocument); typeEdge={ node:{ title:string; number:number; url:string; body:string; }; }; typeResponse={ data:{ search:{ edges: Edge[]}}; }; // Replace with your real GitHub access token const accessToken ="YOUR_GITHUB_ACCESS_TOKEN"; const searchScope ="repo:facebook/docusaurus"; const search =async(input:string):Promise<Response>=>{ const query =` { search(query: "${searchScope}${input}", type: ISSUE, first: 10) { edges { node { ... on PullRequest { title number body url } ... on Issue { title number body url } } } } } `; const response =awaitfetch("https://api.github.com/graphql",{ method:"POST", body:JSON.stringify({ query }), headers:{ Authorization:`Bearer ${accessToken}`, }, }); if(!response.ok){ const error ={ status: response.status, statusText: response.statusText, body:await response.json(), }; connection.console.error( `Error fetching from GitHub: ${JSON.stringify(error)}`, ); } returnawait response.json(); }; connection.onInitialize(()=>{ const result: InitializeResult ={ capabilities:{ textDocumentSync: TextDocumentSyncKind.Incremental, // Tell the client that the server supports code completion completionProvider:{ // We want to listen for the "#" character to trigger our completions triggerCharacters:["#"], }, }, }; return result; }); connection.onCompletion(async(params)=>{ const doc = documents.get(params.textDocument.uri); if(!doc){ returnnull; } const line = doc.getText().split("\n")[params.position.line]; // return early if we don't see our trigger character if(!line.includes("#")){ returnnull; } const input = line.slice(line.lastIndexOf("#")+1); const json =awaitsearch(input); const items = json.data.search.edges.map((edge)=>{ return{ label:`#${edge.node.number}: ${edge.node.title}`, detail:`${edge.node.title}\n\n${edge.node.body}`, textEdit:{ range:{ start:{ line: params.position.line, character: line.lastIndexOf("#"), }, end:{ line: params.position.line, character: params.position.character, }, }, newText:`${edge.node.url}`, }, }; }); return{ isIncomplete:true, items, }; }); // Make the text document manager listen on the connection // for open, change and close text document events documents.listen(connection); // Listen on the connection connection.listen();
It works, but searchScope (e.g., repo:facebook/docusaurus) and our GitHub access token are hard-coded. That's fine for local development, but to get this language server ready to share, we should make those configurable.
Note that the myLSP prefix on the properties matches the string we use in our getConfig function.
Once you've repackaged and reinstalled your extension, you can modify the settings by pressing ctrl+shift+p (cmd+shift+p on Mac) and typing "Open Settings UI"
Once in the Settings UI, search for myLSP to modify your settings.
Changes take effect immediately because we pull the settings in our server as needed.
Language servers let you meet developers where they are: their editor. They give you the power of in-editor tooling without rebuilding your tools for each editor you want to support. They can implement features like completion, go-to-definition, code actions, and more.
The Language Server Protocol (LSP) specifies how a language server should interface with an editor.
import{ createConnection, InitializeResult, TextDocumentSyncKind, TextDocuments, }from"vscode-languageserver/node"; import{ TextDocument }from"vscode-languageserver-textdocument"; const connection =createConnection(); const documents: TextDocuments<TextDocument>=newTextDocuments(TextDocument); connection.onInitialize(()=>{ const result: InitializeResult ={ capabilities:{ textDocumentSync: TextDocumentSyncKind.Incremental, // Tell the client that the server supports code completion completionProvider:{ // We want to listen for the "#" character to trigger our completions triggerCharacters:["#"], }, }, }; return result; }); // Make the text document manager listen on the connection // for open, change and close text document events documents.listen(connection); // Listen on the connection connection.listen();
After our imports, we set up a connection and some documents. The connection handles the communication between the editor (the client) and our code (the server). documents is a store of open files in our editor. documents stays in sync when files open, close, and change.
When the editor starts our server, onInitialize is fired. The editor sends some params describing what it can do (and what it wants our server to do), but we're not using those here, so we'll omit them. We reply with a list of things we can do (primarily, we offer completions triggered by #).
We tell documents to listen on the connection and the connection to listen for communication from the editor.
Our server could now run hosted by the editor (more on that later), but it doesn't do anything useful yet.
Let's add the initial hard-coded completion after our onInitialize.
connection.onCompletion(()=>{ return[ { label:"Cannot set properties of undefined (setting 'minItems')", data:"https://github.com/facebook/docusaurus/issues/9271", }, { label:"docs: fix typo in docs-introduction", data:"https://github.com/facebook/docusaurus/pull/9267", }, { label:"Upgrade notification command does not copy properly", data:"https://github.com/facebook/docusaurus/issues/9239", }, ]; });
While the LSP standardizes how to implement Language Servers and how they talk to editors, there's no good standard for making your editor aware of a language server so that it is ready to be used. For this post, I'll cover VS Code and Neovim.
You connect a language server to VS Code by creating a thin extension layer. To make things as easy as possible for you, I've published a Minimum Viable VS Code Language Server Extension. Follow the directions in that repo and replace the entire contents of server/src/server.ts with the code we're writing in this post.
After following those directions, we'll also need to install node-fetch for the server since the node version packaged with VS Code is too old to include native fetch support.
cd server && npm install node-fetch@2 && npm install --save-dev @types/node-fetch && cd -
Now, you should be able to test your extension with the steps mentioned here. You should be able to open a new file, type #, and then see something like this:
For Neovim, you pass some configuration to vim.lsp.start. For testing, I've put the following in ~/.config/nvim/after/ftplugin/ruby.lua. Note that this location means it only runs in ruby files. Feel free to start the server elsewhere.
GitHub provides a GraphQL API. Get a GitHub access token and have it handy. It appears a classic token with "repo" permissions is required to get the search query to work correctly (at the time of writing).
Here's a query to search the Docusaurus repo for issues and PRs that include the word "bug.”
{ search(query:"repo:facebook/docusaurus bug",type:ISSUE,first:10){ edges{ node{ ...onPullRequest{ title number body url } ...onIssue{ title number body url } } } } }
We could replace repo:facebook/docusaurus with owner:facebook to scope search every repo owned by Facebook (that we have access to).
You can replace the searchScope with your organization or repo name when applying the changes below. Be sure to swap out the placeholder YOUR_GITHUB_ACCESS_TOKEN with your token. In a future post, we'll cover language server configuration to pass in our search scope and access token.
With this information and the documents we initialized earlier, we have everything we need to understand what the user was typing.
connection.onCompletion(async(params)=>{ const doc = documents.get(params.textDocument.uri); if(!doc){ returnnull; } const line = doc.getText().split("\n")[params.position.line]; // return early if we don't see our trigger character if(!line.includes("#")){ returnnull; } const input = line.slice(line.lastIndexOf("#")+1); // ...
After selecting our completion choice, you’ll notice that the # character hangs around. How do we prevent this? And why do we need a trigger character anyway?
If we didn't have a trigger character, this completion would trigger constantly as we type any code. That's wasteful for API requests and means we're doing unnecessary work -- we only want to show issues and PRs in very specific scenarios. So, the behavior should be opt-in, and a trigger character is beneficial.
To prevent the # from hanging around, we can replace our naive insertText with a TextEdit. TextEdits allow you to specify a range in the document to replace with new text. We'll modify our completion item formatting function: