
A health check is a page or endpoint that can indicate whether an application can properly serve requests. Health checks are a useful diagnostic mechanism and it’s handy to have them for all of your application’s dependencies. On the other hand, a failing health check can prevent your application instances from serving requests unaffected by the failing dependency, to the point of complete downtime. How to keep your application’s instances or pods healthy in the face of failing health checks?
There’s a fair amount written on the topic of health check management already (some links below), including approaches such as these:
- Break down services to have simpler functionality to dependency graphs
- Categorize your critical dependencies differently from your nice-to-have dependencies
- Separate liveness checks from readiness checks
- Think about failing-open vs closed when all health checks have gone bad
The Problem
These are the right approaches, but it's tough to get them right on the first shot. In practice this require a fair amount of tuning work to dial in the right behavior. The upshot is that it's fairly common to end up in a situation where a health check starts failing and your application instances or pods are withdrawn from service, but you'd prefer to keep them up and running.
This Redis healthcheck is failing and taking our pods out of service, but the apps are still mostly functional. How do we fix this immediately?
Malleability To The Rescue
To deal with a problem right now, we took an alternative approach: dynamically manage an ignore-list of health checks that will be excluded from aggregation into an overall health status.
We recently encountered an issue with one of our Redis hosts which caused downtime in our staging environment as pods considered unhealthy were withdrawn from service (despite not affecting most core functionality). Once we realized what’s going on, I quickly subclassed Micronaut's DefaultHealthAggregator and created a dynamically configured ignore list to exclude certain health checks. I also added logging to gain better visibility into failing health checks. These changes will give us more visibility and flexibility to quickly handle similar dependency failures in the future.
Micronaut Health Checks Example
@Singleton
@Requires(beans = HealthEndpoint.class)
@Replaces(bean = DefaultHealthAggregator.class)
public class PrefabHealthAggregator extends DefaultHealthAggregator {
private static final Logger LOG = LoggerFactory.getLogger(PrefabHealthAggregator.class);
private static final String CONFIG_KEY = "micronaut.ignored.health.checks";
private final Value<List<String>> ignoredCheckNames;
public PrefabHealthAggregator(
ConfigClient configClient,
ApplicationConfiguration applicationConfiguration
) {
super(applicationConfiguration);
this.ignoredCheckNames = configClient.liveStringList(CONFIG_KEY);
}
@Override
protected HealthStatus calculateOverallStatus(List<HealthResult> results) {
List<String> ignoredResultNames = ignoredCheckNames.orElseGet(Collections::emptyList);
return results
.stream()
.filter(healthResult -> {
if (ignoredResultNames.contains(healthResult.getName())) {
LOG.warn(
"Ignoring health check {} with status {} and details {} based on prefab config {}",
healthResult.getName(),
healthResult.getStatus(),
healthResult.getDetails(),
CONFIG_KEY
);
return false;
}
if (healthResult.getStatus() != HealthStatus.UP) {
LOG.warn(
"Unhealthy status for healthcheck {} with status {} and details {}. To ignore add name to prefab config {}",
healthResult.getName(),
healthResult.getStatus(),
healthResult.getDetails(),
CONFIG_KEY
);
} else {
LOG.debug(
"passing health result named: {} with status {} and details {}",
healthResult.getName(),
healthResult.getStatus(),
healthResult.getDetails()
);
}
return true;
})
.map(HealthResult::getStatus)
.sorted()
.distinct()
.reduce((a, b) -> b)
.orElse(HealthStatus.UNKNOWN);
}
}
Ignoring a Health Check & Verifying It Works
Now in dynamic configuration we can add a list of health checks to ignore. We'll create a List<String> with the name micronaut.ignored.health.checks and then add the name of the health check we want to ignore. For testing, let's add redis to the list in staging.
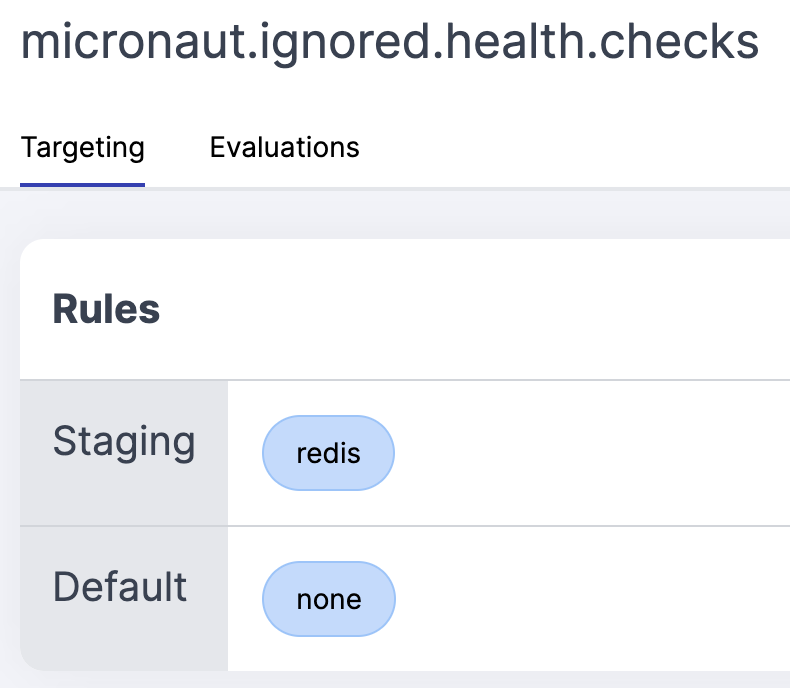
Dynamic configuration will propagate this value out to all connected SDKs. But how do we know that it's all working? Well, luckily for us we have some useful debug logging. To verify that it's working, we can turn on debug logging for the PrefabHealthAggregator class in staging using dynamic logging.

Then we can look over in our logging aggregator and see that the health checks are being ignored:
WARN 10:52:10 Ignoring healthcheck redis with status UP and details {} based on prefab config micronaut.ignored.health.checks
DEBUG 10:52:10 passing healthcheck grpc-server with status UP and details {host=localhost, port=60001}
DEBUG 10:52:10 passing healthcheck diskSpace with status UP and details {total=101203873792, free=49808666624, threshold=10485760}
DEBUG 10:52:10 passing healthcheck service with status UP and details null
DEBUG 10:52:10 passing healthcheck compositeDiscoveryClient() with status UP and details {services={}}
DEBUG 10:52:10 passing healthcheck jdbc:postgresql://1.1.1.1:5432 with status UP and details {database=PostgreSQL, version=15.2}
Summary
Healthchecks are great, but they take some tuning to get right. Unfortunately, getting these wrong can cuase unnecessary downtime.
Luckily, we can use dynamic configuration to quickly tune our healthchecks to get the right behavior as quickly as possible.